But first, a little bit of context
Traditionally, High-Performance Computing clusters face a challenge when dealing with modern, data-intensive applications. Existing HPC storage systems, long designed with spinning disks to provide efficient and parallel sequential read/write operations, often become bottlenecks for modern workloads generated by AI/ML or CryoEM applications. Those demand substantial data storage and processing capabilities, putting a strain on traditional systems.
So to accommodate those new needs and future evolution of the HPC I/O landscape, we at Stanford Research Computing, with the generous support of the Vice Provost and Dean of Research, have been hard at work for over two years, revamping Sherlock's scratch with an all-flash system.
And it was not just a matter of taking delivery of a new turn-key system. As most things we do, it was done entirely in-house: from the original vendor-agnostic design, upgrade plan, budget requests, procurement, gradual in-place hardware replacement at the Stanford Research Computing Facility (SRCF), deployment and validation, performance benchmarks, to the final production stages, all of those steps were performed with minimum disruption for all Sherlock users.
The technical details
The /scratch file system on Sherlock is using Lustre, an open-source, parallel file system that supports many requirements of leadership class HPC environments. And as you probably know by now, Stanford Research Computing loves open source! We actively contribute to the Lustre community and are a proud member of OpenSFS, a non-profit industry organization that supports vendor-neutral development and promotion of Lustre.
In Lustre, file metadata and data are stored separately, with Object Storage Servers (OSS) serving file data on the network. Each OSS pair and associated storage devices forms an I/O cell, and Sherlock's scratch has just bid farewell to its old HDD-based I/O cells. In their place, new flash-based I/O cells have taken the stage, each equipped with 96 x 15.35TB SSDs, delivering mind-blowing performance.
Sherlock’s /scratch has 8 I/O cells and the goal was to replace every one of them. Our new I/O cell has 2 OSS with Infiniband HDR at 200Gb/s (or 25GB/s) connected to 4 storage chassis, each with 24 x 15.35TB SSD (dual-attached 12Gb/s SAS), as pictured below:

Of course, you can’t just replace each individual rotating hard-drive with a SSD, there are some infrastructure changes required, and some reconfiguration needed. The upgrade, executed between January 2023 and January 2024, was a seamless transition. Old HDD-based I/O cells were gracefully retired, one by one, while flash-based ones progressively replaced them, gradually boosting performance for all Sherlock users throughout the year.
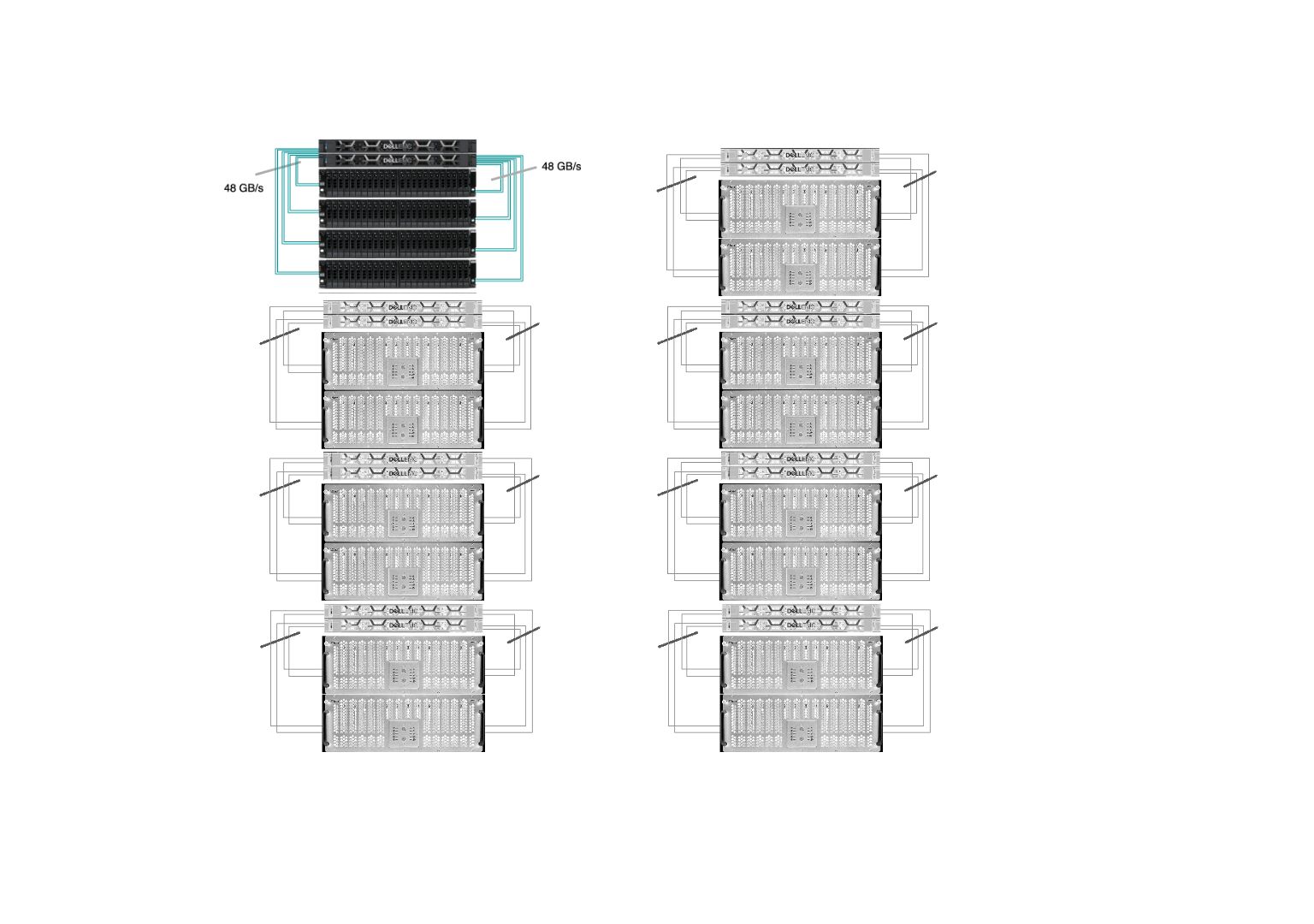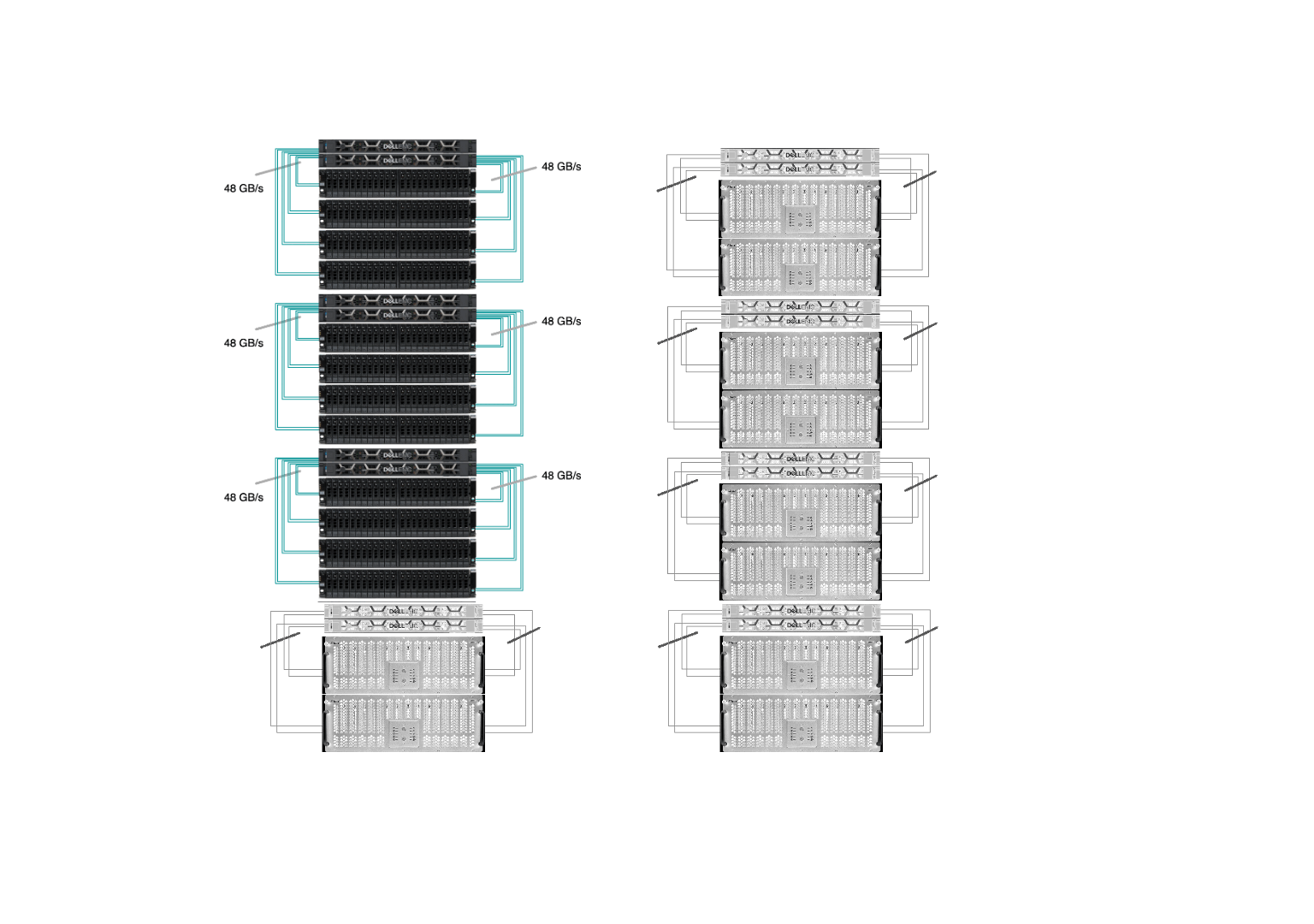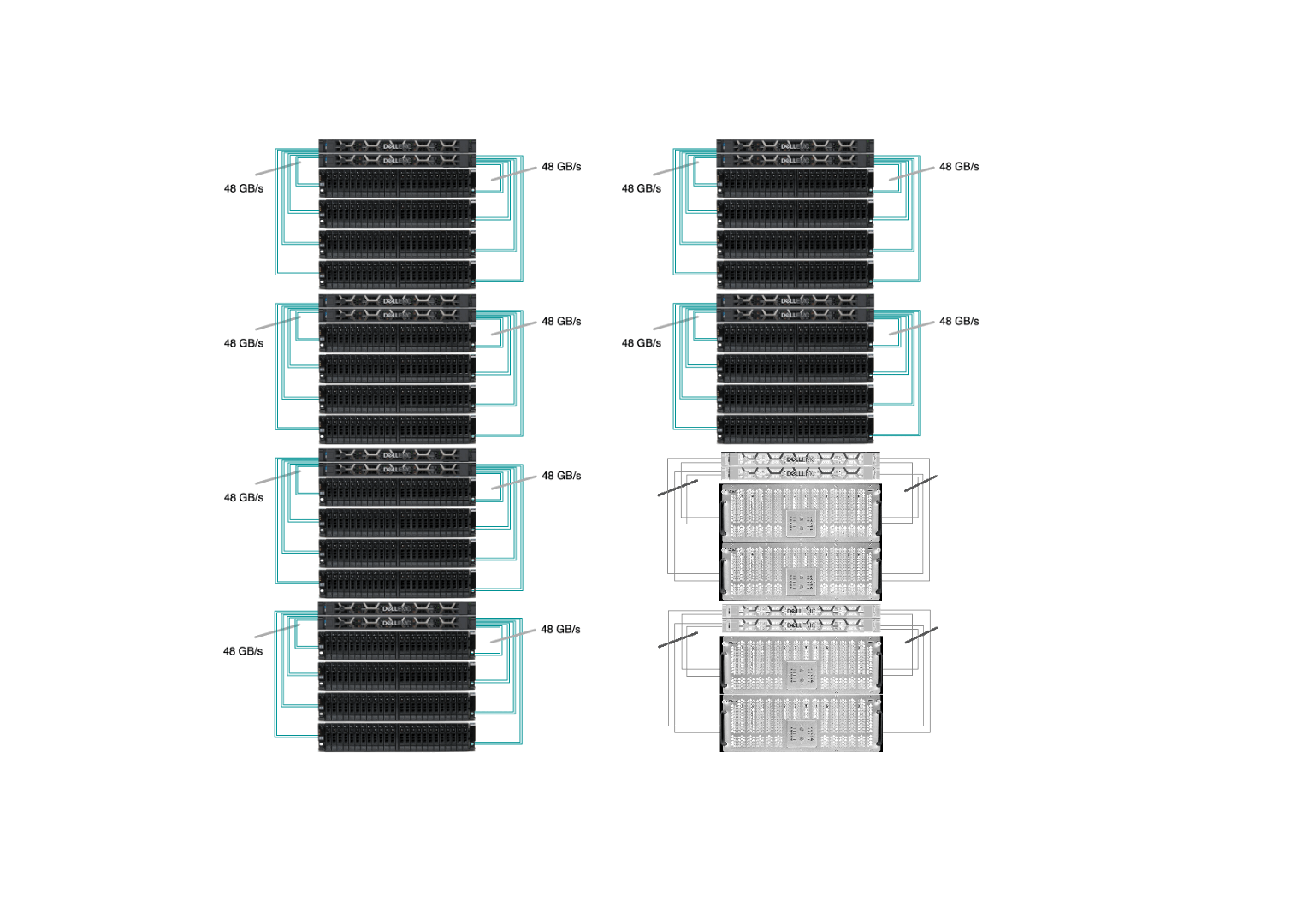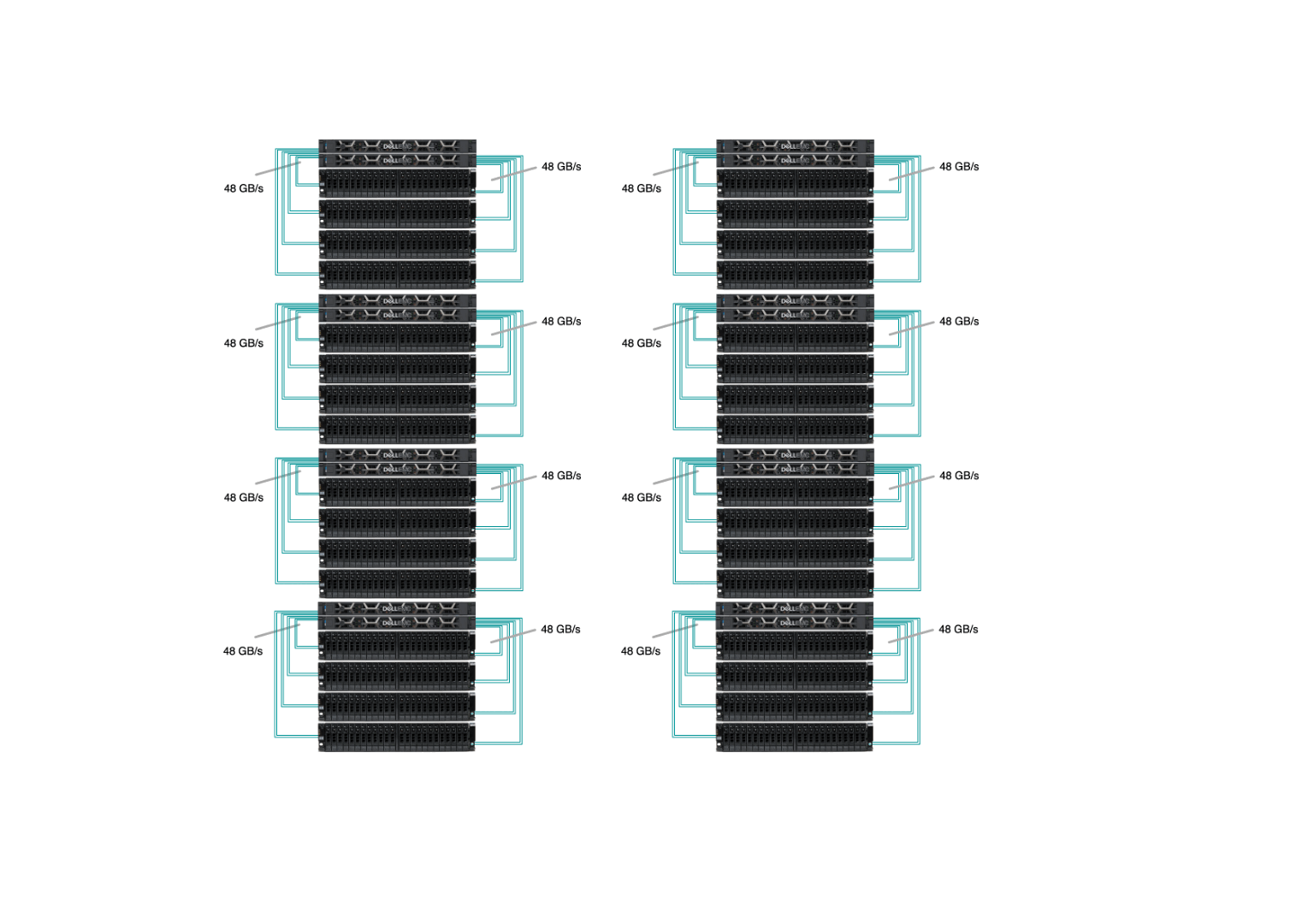
All of those replacements happened while the file system was up and running, serving data to the thousands of computing jobs that run on Sherlock every day. Driven by our commitment to minimize disruptions to users, our top priority was to ensure uninterrupted access to data throughout the upgrade. Data migration is never fun, and we wanted to avoid having to ask users to manually transfer their files to a new, separate storage system. This is why we developed and contributed a new feature in Lustre, which allowed us to seamlessly remove existing storage devices from the file system, before the new flash drives could be added. More technical details about the upgrade have been presented during the LAD’22 conference.
Today, we are happy to announce that the upgrade is officially complete, and Sherlock stands proud with a whopping 9,824 TB of solid-state storage in production. No more spinning disks in sight!
Key benefits
For users, the immediately visible benefits are quicker access to their files, faster data transfers, shorter job execution times for I/O intensive applications. More specifically, every key metric has been improved:
IOPS: over 100x (results may vary, see below)
Backend bandwidth: 6x (128 GB/s to 768 GB/s)
Frontend bandwidth: 2x (200 GB/s to 400 GB/s)
Usable volume: 1.6x (6.1 PB to 9.8 PB)
In terms of measured improvement, the graph below shows the impact of moving to full-flash storage for reading data from 1, 8 and 16 compute nodes, compared to the previous /scratch file system:
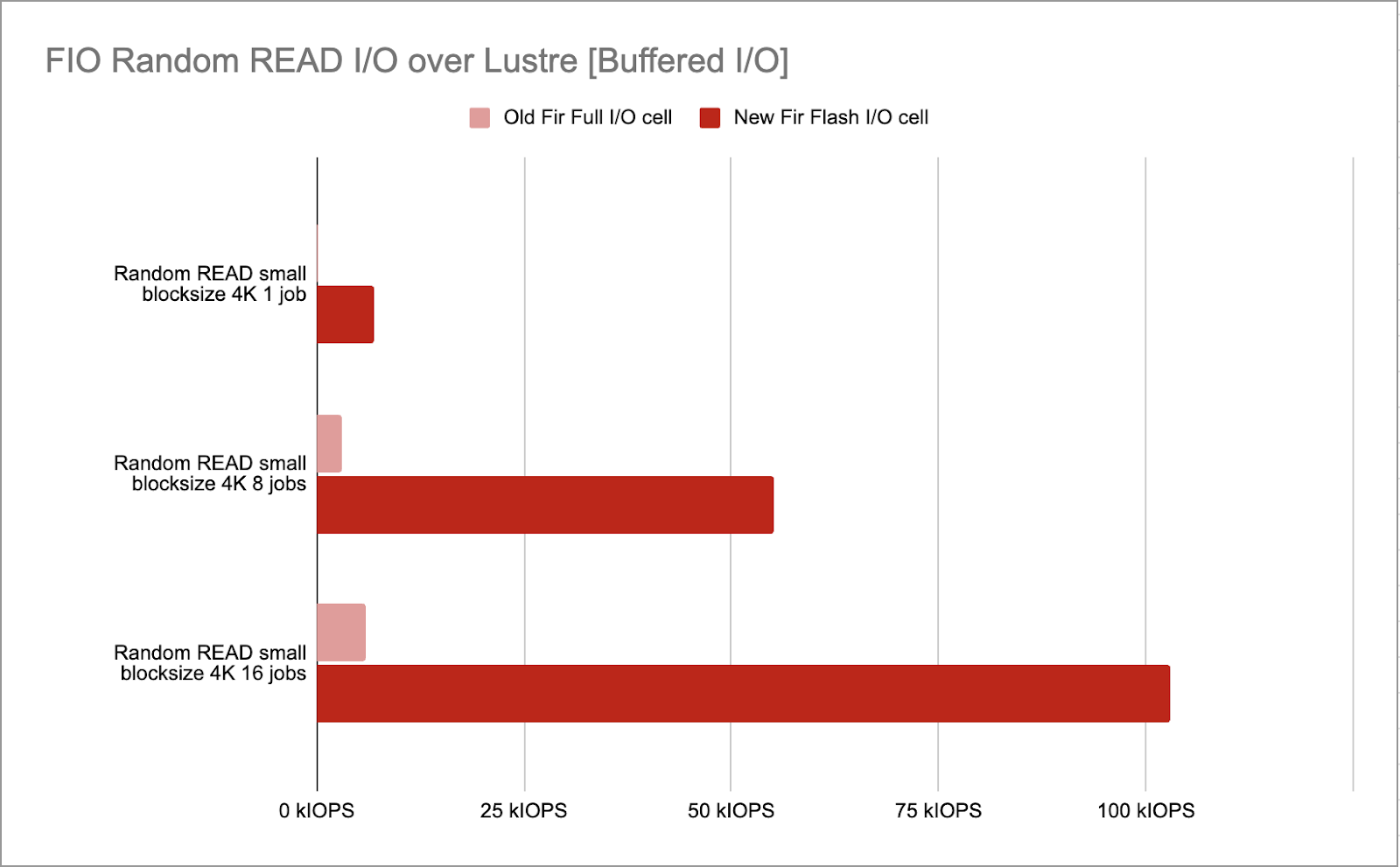
And we even tried to replicate the I/O patterns of AlphaFold, a well-known AI model to predict protein structure, and the benefits are quite significant, with up to 125x speedups in some cases:
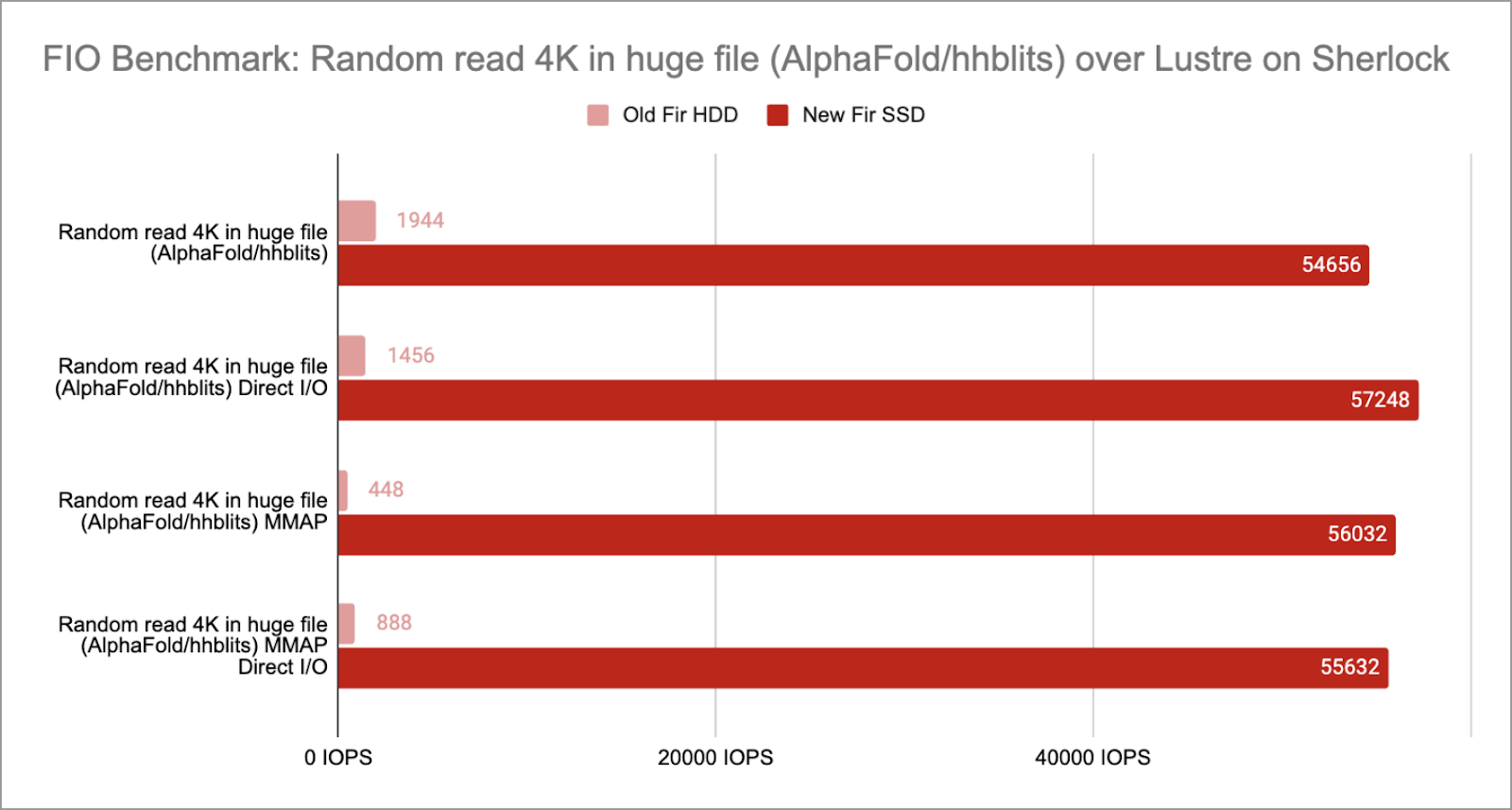
This upgrade is a major improvement that will benefit all Sherlock users, and Sherlock’s enhanced I/O capabilities will allow them to approach data-intensive tasks with unprecedented efficiency. We hope it will help support the ever-increasing computing needs of the Stanford research community, and enable even more breakthroughs and discoveries.
As usual, if you have any question or comment, please don’t hesitate to reach out to Research Computing at [email protected]. 🚀🔧
But first, a little bit of context
Traditionally, High-Performance Computing clusters face a challenge when dealing with modern, data-intensive applications. Existing HPC storage systems, long designed with spinning disks to provide efficient and parallel sequential read/write operations, often become bottlenecks for modern workloads generated by AI/ML or CryoEM applications. Those demand substantial data storage and processing capabilities, putting a strain on traditional systems.
So to accommodate those new needs and future evolution of the HPC I/O landscape, we at Stanford Research Computing, with the generous support of the Vice Provost and Dean of Research, have been hard at work for over two years, revamping Sherlock's scratch with an all-flash system.
And it was not just a matter of taking delivery of a new turn-key system. As most things we do, it was done entirely in-house: from the original vendor-agnostic design, upgrade plan, budget requests, procurement, gradual in-place hardware replacement at the Stanford Research Computing Facility (SRCF), deployment and validation, performance benchmarks, to the final production stages, all of those steps were performed with minimum disruption for all Sherlock users.
The technical details
The /scratch file system on Sherlock is using Lustre, an open-source, parallel file system that supports many requirements of leadership class HPC environments. And as you probably know by now, Stanford Research Computing loves open source! We actively contribute to the Lustre community and are a proud member of OpenSFS, a non-profit industry organization that supports vendor-neutral development and promotion of Lustre.
In Lustre, file metadata and data are stored separately, with Object Storage Servers (OSS) serving file data on the network. Each OSS pair and associated storage devices forms an I/O cell, and Sherlock's scratch has just bid farewell to its old HDD-based I/O cells. In their place, new flash-based I/O cells have taken the stage, each equipped with 96 x 15.35TB SSDs, delivering mind-blowing performance.
Sherlock’s /scratch has 8 I/O cells and the goal was to replace every one of them. Our new I/O cell has 2 OSS with Infiniband HDR at 200Gb/s (or 25GB/s) connected to 4 storage chassis, each with 24 x 15.35TB SSD (dual-attached 12Gb/s SAS), as pictured below:
Of course, you can’t just replace each individual rotating hard-drive with a SSD, there are some infrastructure changes required, and some reconfiguration needed. The upgrade, executed between January 2023 and January 2024, was a seamless transition. Old HDD-based I/O cells were gracefully retired, one by one, while flash-based ones progressively replaced them, gradually boosting performance for all Sherlock users throughout the year.
All of those replacements happened while the file system was up and running, serving data to the thousands of computing jobs that run on Sherlock every day. Driven by our commitment to minimize disruptions to users, our top priority was to ensure uninterrupted access to data throughout the upgrade. Data migration is never fun, and we wanted to avoid having to ask users to manually transfer their files to a new, separate storage system. This is why we developed and contributed a new feature in Lustre, which allowed us to seamlessly remove existing storage devices from the file system, before the new flash drives could be added. More technical details about the upgrade have been presented during the LAD’22 conference.
Today, we are happy to announce that the upgrade is officially complete, and Sherlock stands proud with a whopping 9,824 TB of solid-state storage in production. No more spinning disks in sight!
Key benefits
For users, the immediately visible benefits are quicker access to their files, faster data transfers, shorter job execution times for I/O intensive applications. More specifically, every key metric has been improved:
IOPS: over 100x (results may vary, see below)
Backend bandwidth: 6x (128 GB/s to 768 GB/s)
Frontend bandwidth: 2x (200 GB/s to 400 GB/s)
Usable volume: 1.6x (6.1 PB to 9.8 PB)
In terms of measured improvement, the graph below shows the impact of moving to full-flash storage for reading data from 1, 8 and 16 compute nodes, compared to the previous /scratch file system:
And we even tried to replicate the I/O patterns of AlphaFold, a well-known AI model to predict protein structure, and the benefits are quite significant, with up to 125x speedups in some cases:
This upgrade is a major improvement that will benefit all Sherlock users, and Sherlock’s enhanced I/O capabilities will allow them to approach data-intensive tasks with unprecedented efficiency. We hope it will help support the ever-increasing computing needs of the Stanford research community, and enable even more breakthroughs and discoveries.
As usual, if you have any question or comment, please don’t hesitate to reach out to Research Computing at [email protected]. 🚀🔧
To help users inform those choices, we’ve just added a new tool to the module list on Sherlock.
ruse is command-line tool developed by Jan Moren which facilitates measuring processes’ resource usage. It periodically measures the resource use of a process and its sub-processes, and can help users find out how much resource to allocate to their jobs. It will determine the actual memory, execution time and cores that individual programs or MPI applications need to request in their job submission options.You’ll find more information and some examples in the Sherlock documentation at https://www.sherlock.stanford.edu/docs/user-guide/running-jobs/#resource-requests
Hopefully
ruse will make it easier to write job resource requests , and allow users to get a better understanding of their applications’ behavior to take better advantage of Sherlock’s capabilities.As usual, if you have any question or comment, please don’t hesitate to reach out at [email protected].
]]>To help users inform those choices, we’ve just added a new tool to the module list on Sherlock.
ruse is command-line tool developed by Jan Moren which facilitates measuring processes’ resource usage. It periodically measures the resource use of a process and its sub-processes, and can help users find out how much resource to allocate to their jobs. It will determine the actual memory, execution time and cores that individual programs or MPI applications need to request in their job submission options.You’ll find more information and some examples in the Sherlock documentation at https://www.sherlock.stanford.edu/docs/user-guide/running-jobs/#resource-requests
Hopefully
ruse will make it easier to write job resource requests , and allow users to get a better understanding of their applications’ behavior to take better advantage of Sherlock’s capabilities.As usual, if you have any question or comment, please don’t hesitate to reach out at [email protected].
]]>normal partition on Sherlock is getting an upgrade!With the addition of 24 brand new SH3_CBASE.1 compute nodes, each featuring one AMD EPYC 7543 Milan 32-core CPU and 256 GB of RAM, Sherlock users now have 768 more CPU cores at there disposal. Those new nodes will complete the existing 154 compute nodes and 4,032 core in that partition, for a new total of 178 nodes and 4,800 CPU cores.
The
normal partition is Sherlock’s shared pool of compute nodes, which is available free of charge to all Stanford Faculty members and their research teams, to support their wide range of computing needs. In addition to this free set of computing resources, Faculty can supplement these shared nodes by purchasing additional compute nodes, and become Sherlock owners. By investing in the cluster, PI groups not only receive exclusive access to the nodes they purchased, but also get access to all of the other owner compute nodes when they're not in use, thus giving them access to the whole breadth of Sherlock resources, currently over over 1,500 compute nodes, 46,000 CPU cores and close to 4 PFLOPS of computing power.
We hope that this new expansion of the
normal partition, made possible thanks to additional funding provided by the University Budget Group as part of the FY23 budget cycle, will help support the ever-increasing computing needs of the Stanford research community, and enable even more breakthroughs and discoveries.As usual, if you have any question or comment, please don’t hesitate to reach out at [email protected].
]]>
normal partition on Sherlock is getting an upgrade!With the addition of 24 brand new SH3_CBASE.1 compute nodes, each featuring one AMD EPYC 7543 Milan 32-core CPU and 256 GB of RAM, Sherlock users now have 768 more CPU cores at there disposal. Those new nodes will complete the existing 154 compute nodes and 4,032 core in that partition, for a new total of 178 nodes and 4,800 CPU cores.
The
normal partition is Sherlock’s shared pool of compute nodes, which is available free of charge to all Stanford Faculty members and their research teams, to support their wide range of computing needs. In addition to this free set of computing resources, Faculty can supplement these shared nodes by purchasing additional compute nodes, and become Sherlock owners. By investing in the cluster, PI groups not only receive exclusive access to the nodes they purchased, but also get access to all of the other owner compute nodes when they're not in use, thus giving them access to the whole breadth of Sherlock resources, currently over over 1,500 compute nodes, 46,000 CPU cores and close to 4 PFLOPS of computing power.
We hope that this new expansion of the
normal partition, made possible thanks to additional funding provided by the University Budget Group as part of the FY23 budget cycle, will help support the ever-increasing computing needs of the Stanford research community, and enable even more breakthroughs and discoveries.As usual, if you have any question or comment, please don’t hesitate to reach out at [email protected].
]]>
A new version of the sh_dev tool has been released, that leverages a recently-added Slurm feature.
Slurm 20.11 introduced a new “interactive step” , designed to be used with salloc to automatically launch a terminal on an allocated compute node. This new type of job step resolves a number of problems with the previous interactive job approaches, both in terms of accounting and resource allocation.
What is this about?
In previous versions, launching an interactive job with srun --pty bash would create a step 0, that was consuming resources, especially Generic Resources (GRES, ie. GPUs). Among other things, it made it impossible to use srun within that allocation to launch subsequent steps. Any attempt would result in a “step creation temporarily disabled” error message.
Now, with this new feature, you can use salloc to directly open a shell on a compute node. The new interactive step won’t consume any of the allocated resources, so you’ll be able to start additional steps with srun within your allocation. sh_dev (aka sdev) has been updated to use interactive steps.
What changes?
For sh_dev
On the surface, nothing changes: you can continue to use sh_dev exactly like before, to start an interactive session on one of the compute nodes dedicated to that task (the default), or on a node in any partition (which is particularly popular among node owners). You’ll be able to use the same options, with the same features (including X11 forwarding).
Under the hood, though, you’ll be leveraging the new interactive step automatically.
For salloc
If you use salloc on a regular basis, the main change is that the resulting shell will open on the first allocated node, instead of the node you ran salloc on:
[kilian@sh01-ln01 login ~]$ salloc
salloc: job 25753490 has been allocated resources
salloc: Granted job allocation 25753490
salloc: Nodes sh02-01n46 are ready for job
[kilian@sh02-01n46 ~] (job 25753490) $ If you want to keep that initial shell on the submission host, you can simply specify a command as an argument, and the resulting command will continue to be executed as the calling user on the calling host:
[kilian@sh01-ln01 login ~]$ salloc bash
salloc: job 25752889 has been allocated resources
salloc: Granted job allocation 25752889
salloc: Nodes sh02-01n46 are ready for job
[kilian@sh01-ln01 login ~] (job 25752889) $For srun
If you’re used to run srun —pty bash to get a shell on a compute node, you can continue to do so (as long as you don’t intend to run additional steps within the allocation).
But you can also just type salloc, get a more usable shell, and save 60% in keystrokes!
Happy computing! And as usual, please feel free to reach out if you have comments or questions.
]]>A new version of the sh_dev tool has been released, that leverages a recently-added Slurm feature.
Slurm 20.11 introduced a new “interactive step” , designed to be used with salloc to automatically launch a terminal on an allocated compute node. This new type of job step resolves a number of problems with the previous interactive job approaches, both in terms of accounting and resource allocation.
What is this about?
In previous versions, launching an interactive job with srun --pty bash would create a step 0, that was consuming resources, especially Generic Resources (GRES, ie. GPUs). Among other things, it made it impossible to use srun within that allocation to launch subsequent steps. Any attempt would result in a “step creation temporarily disabled” error message.
Now, with this new feature, you can use salloc to directly open a shell on a compute node. The new interactive step won’t consume any of the allocated resources, so you’ll be able to start additional steps with srun within your allocation. sh_dev (aka sdev) has been updated to use interactive steps.
What changes?
For sh_dev
On the surface, nothing changes: you can continue to use sh_dev exactly like before, to start an interactive session on one of the compute nodes dedicated to that task (the default), or on a node in any partition (which is particularly popular among node owners). You’ll be able to use the same options, with the same features (including X11 forwarding).
Under the hood, though, you’ll be leveraging the new interactive step automatically.
For salloc
If you use salloc on a regular basis, the main change is that the resulting shell will open on the first allocated node, instead of the node you ran salloc on:
[kilian@sh01-ln01 login ~]$ salloc
salloc: job 25753490 has been allocated resources
salloc: Granted job allocation 25753490
salloc: Nodes sh02-01n46 are ready for job
[kilian@sh02-01n46 ~] (job 25753490) $ If you want to keep that initial shell on the submission host, you can simply specify a command as an argument, and the resulting command will continue to be executed as the calling user on the calling host:
[kilian@sh01-ln01 login ~]$ salloc bash
salloc: job 25752889 has been allocated resources
salloc: Granted job allocation 25752889
salloc: Nodes sh02-01n46 are ready for job
[kilian@sh01-ln01 login ~] (job 25752889) $For srun
If you’re used to run srun —pty bash to get a shell on a compute node, you can continue to do so (as long as you don’t intend to run additional steps within the allocation).
But you can also just type salloc, get a more usable shell, and save 60% in keystrokes!
Happy computing! And as usual, please feel free to reach out if you have comments or questions.
]]>Now, when you’re in the context of a Slurm job, your shell prompt will automatically display that job’s id, so you always know where you’re at.
For instance, when you submit an interactive job with
sdev, your prompt will automatically be updated to not only display the host name of the compute node you’ve been allocated, but also the id of the job your new shell is running in:[kilian@sh03-ln06 login ~]$ sdev
srun: job 24333698 queued and waiting for resources
srun: job 24333698 has been allocated resources
[kilian@sh02-01n58 ~] (job 24333698) $Use cases
This additional information could prove particularly useful in situations where the fact that you’re running in the context of a Slurm job is not immediately visible.
Dynamic resource allocation
For instance, when allocating resources with salloc, the scheduler will start a new shell on the same node you’re on, but nothing will differentiate that shell from your login shell, so it’s pretty easy to forget that you’re in a job (and also that if you exit that shell, you’ll terminate your resource allocation).
So now, when you use salloc, your prompt will be updated as well, so you’ll always know you’re in a job:
[kilian@sh03-ln06 login ~]$ salloc -N 4 --time 2:0:0
salloc: Pending job allocation 24333807
[...]
[kilian@sh03-ln06 login ~] (job 24333807) $ srun hostname
sh03-01n25.int
sh03-01n28.int
sh03-01n27.int
sh03-01n30.int
[kilian@sh03-ln06 login ~] (job 24333807) $ exit
salloc: Relinquishing job allocation 24333807
[kilian@sh03-ln06 login ~]$Connecting to computing nodes
Another case is when you need to connect via SSH to compute nodes where your jobs are running. The scheduler will automatically inject your SSH session in the context of the running job, and now, you’ll see that jobid automatically displayed in your prompt, like this:
[kilian@sh03-ln06 login ~]$ sbatch sleep.sbatch
Submitted batch job 24334257
[kilian@sh03-ln06 login ~]$ squeue -j 24334257 -O nodelist -h
sh02-01n47
[kilian@sh03-ln06 login ~]$ ssh sh02-01n47
------------------------------------------
Sherlock compute node
>> deployed Fri Apr 30 23:36:45 PDT 2021
------------------------------------------
[kilian@sh02-01n47 ~] (job 24334257) $Step creation temporarily disabled
Have you ever encountered that message when submitting a job?step creation temporarily disabled, retrying (Requested nodes are busy)
That usually means that you’re trying to run a job from within a job: the scheduler tries to allocate resources that are already allocated to your current shell, so it waits until those resources become available. Of course, that never happens, so it waits here forever. Or until your job time runs out…
Now, a quick glance at your prompt will show you that you’re already in a job, so it will hopefully help catching those situations:
[kilian@sh03-ln06 login ~]$ srun --pty bash
srun: job 24334422 queued and waiting for resources
srun: job 24334422 has been allocated resources
[kilian@sh02-01n47 ~] (job 24334422) $ srun --pty bash
srun: Job 24334422 step creation temporarily disabled, retrying (Requested nodes are busy)
srun: Job 24334422 step creation still disabled, retrying (Requested nodes are busy)
srun: Job 24334422 step creation still disabled, retrying (Requested nodes are busy)
srun: Job 24334422 step creation still disabled, retrying (Requested nodes are busy)We hope that small improvement will help make things easier and more visible when navigating jobs on Sherlock. Sometimes, it’s the little things, they say. :)
As usual, please feel free to reach out if you have comments or questions!
Now, when you’re in the context of a Slurm job, your shell prompt will automatically display that job’s id, so you always know where you’re at.
For instance, when you submit an interactive job with
sdev, your prompt will automatically be updated to not only display the host name of the compute node you’ve been allocated, but also the id of the job your new shell is running in:[kilian@sh03-ln06 login ~]$ sdev
srun: job 24333698 queued and waiting for resources
srun: job 24333698 has been allocated resources
[kilian@sh02-01n58 ~] (job 24333698) $Use cases
This additional information could prove particularly useful in situations where the fact that you’re running in the context of a Slurm job is not immediately visible.
Dynamic resource allocation
For instance, when allocating resources with salloc, the scheduler will start a new shell on the same node you’re on, but nothing will differentiate that shell from your login shell, so it’s pretty easy to forget that you’re in a job (and also that if you exit that shell, you’ll terminate your resource allocation).
So now, when you use salloc, your prompt will be updated as well, so you’ll always know you’re in a job:
[kilian@sh03-ln06 login ~]$ salloc -N 4 --time 2:0:0
salloc: Pending job allocation 24333807
[...]
[kilian@sh03-ln06 login ~] (job 24333807) $ srun hostname
sh03-01n25.int
sh03-01n28.int
sh03-01n27.int
sh03-01n30.int
[kilian@sh03-ln06 login ~] (job 24333807) $ exit
salloc: Relinquishing job allocation 24333807
[kilian@sh03-ln06 login ~]$Connecting to computing nodes
Another case is when you need to connect via SSH to compute nodes where your jobs are running. The scheduler will automatically inject your SSH session in the context of the running job, and now, you’ll see that jobid automatically displayed in your prompt, like this:
[kilian@sh03-ln06 login ~]$ sbatch sleep.sbatch
Submitted batch job 24334257
[kilian@sh03-ln06 login ~]$ squeue -j 24334257 -O nodelist -h
sh02-01n47
[kilian@sh03-ln06 login ~]$ ssh sh02-01n47
------------------------------------------
Sherlock compute node
>> deployed Fri Apr 30 23:36:45 PDT 2021
------------------------------------------
[kilian@sh02-01n47 ~] (job 24334257) $Step creation temporarily disabled
Have you ever encountered that message when submitting a job?step creation temporarily disabled, retrying (Requested nodes are busy)
That usually means that you’re trying to run a job from within a job: the scheduler tries to allocate resources that are already allocated to your current shell, so it waits until those resources become available. Of course, that never happens, so it waits here forever. Or until your job time runs out…
Now, a quick glance at your prompt will show you that you’re already in a job, so it will hopefully help catching those situations:
[kilian@sh03-ln06 login ~]$ srun --pty bash
srun: job 24334422 queued and waiting for resources
srun: job 24334422 has been allocated resources
[kilian@sh02-01n47 ~] (job 24334422) $ srun --pty bash
srun: Job 24334422 step creation temporarily disabled, retrying (Requested nodes are busy)
srun: Job 24334422 step creation still disabled, retrying (Requested nodes are busy)
srun: Job 24334422 step creation still disabled, retrying (Requested nodes are busy)
srun: Job 24334422 step creation still disabled, retrying (Requested nodes are busy)We hope that small improvement will help make things easier and more visible when navigating jobs on Sherlock. Sometimes, it’s the little things, they say. :)
As usual, please feel free to reach out if you have comments or questions!