But first, a little bit of context
Traditionally, High-Performance Computing clusters face a challenge when dealing with modern, data-intensive applications. Existing HPC storage systems, long designed with spinning disks to provide efficient and parallel sequential read/write operations, often become bottlenecks for modern workloads generated by AI/ML or CryoEM applications. Those demand substantial data storage and processing capabilities, putting a strain on traditional systems.
So to accommodate those new needs and future evolution of the HPC I/O landscape, we at Stanford Research Computing, with the generous support of the Vice Provost and Dean of Research, have been hard at work for over two years, revamping Sherlock's scratch with an all-flash system.
And it was not just a matter of taking delivery of a new turn-key system. As most things we do, it was done entirely in-house: from the original vendor-agnostic design, upgrade plan, budget requests, procurement, gradual in-place hardware replacement at the Stanford Research Computing Facility (SRCF), deployment and validation, performance benchmarks, to the final production stages, all of those steps were performed with minimum disruption for all Sherlock users.
The technical details
The /scratch file system on Sherlock is using Lustre, an open-source, parallel file system that supports many requirements of leadership class HPC environments. And as you probably know by now, Stanford Research Computing loves open source! We actively contribute to the Lustre community and are a proud member of OpenSFS, a non-profit industry organization that supports vendor-neutral development and promotion of Lustre.
In Lustre, file metadata and data are stored separately, with Object Storage Servers (OSS) serving file data on the network. Each OSS pair and associated storage devices forms an I/O cell, and Sherlock's scratch has just bid farewell to its old HDD-based I/O cells. In their place, new flash-based I/O cells have taken the stage, each equipped with 96 x 15.35TB SSDs, delivering mind-blowing performance.
Sherlock’s /scratch has 8 I/O cells and the goal was to replace every one of them. Our new I/O cell has 2 OSS with Infiniband HDR at 200Gb/s (or 25GB/s) connected to 4 storage chassis, each with 24 x 15.35TB SSD (dual-attached 12Gb/s SAS), as pictured below:

Of course, you can’t just replace each individual rotating hard-drive with a SSD, there are some infrastructure changes required, and some reconfiguration needed. The upgrade, executed between January 2023 and January 2024, was a seamless transition. Old HDD-based I/O cells were gracefully retired, one by one, while flash-based ones progressively replaced them, gradually boosting performance for all Sherlock users throughout the year.
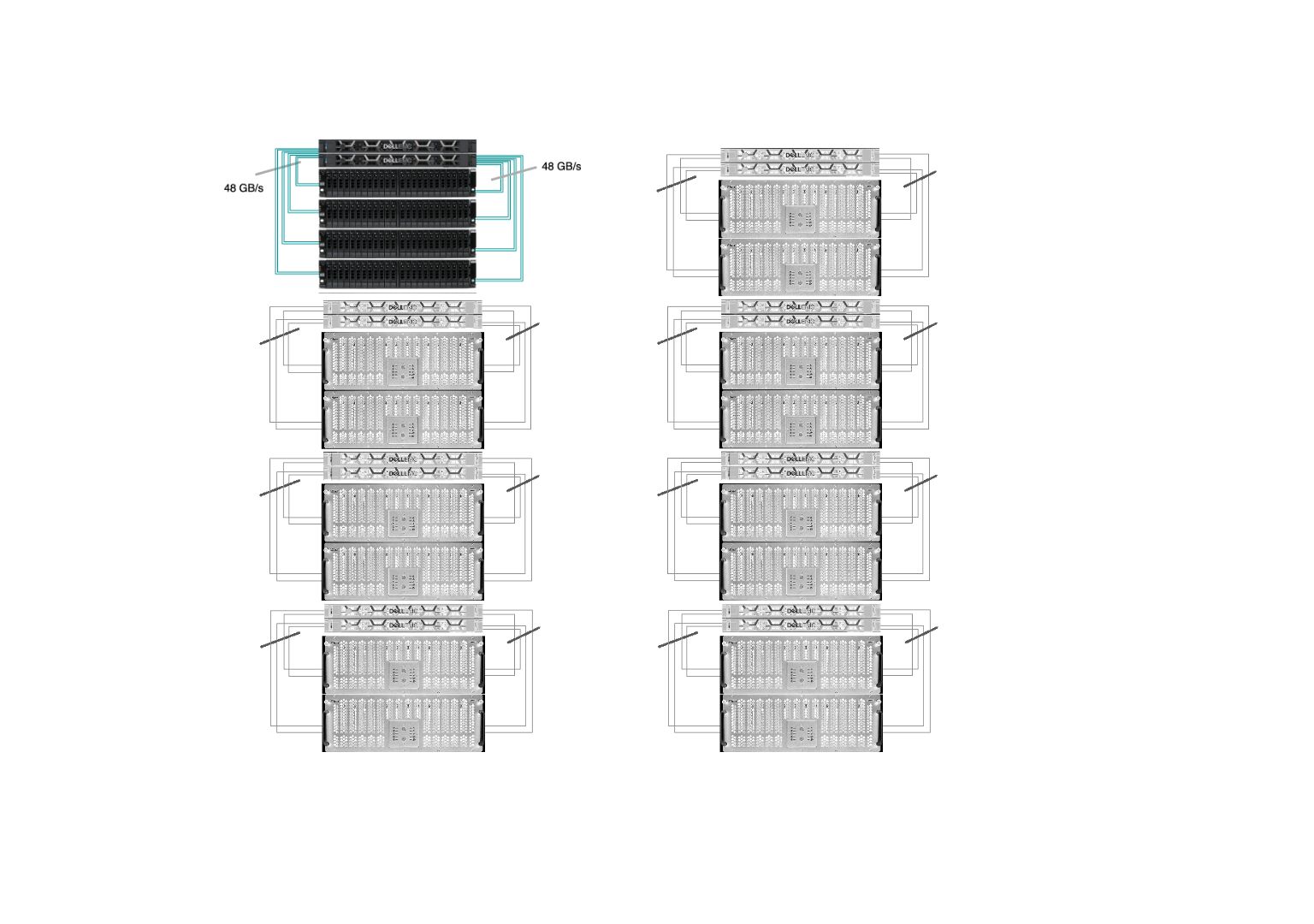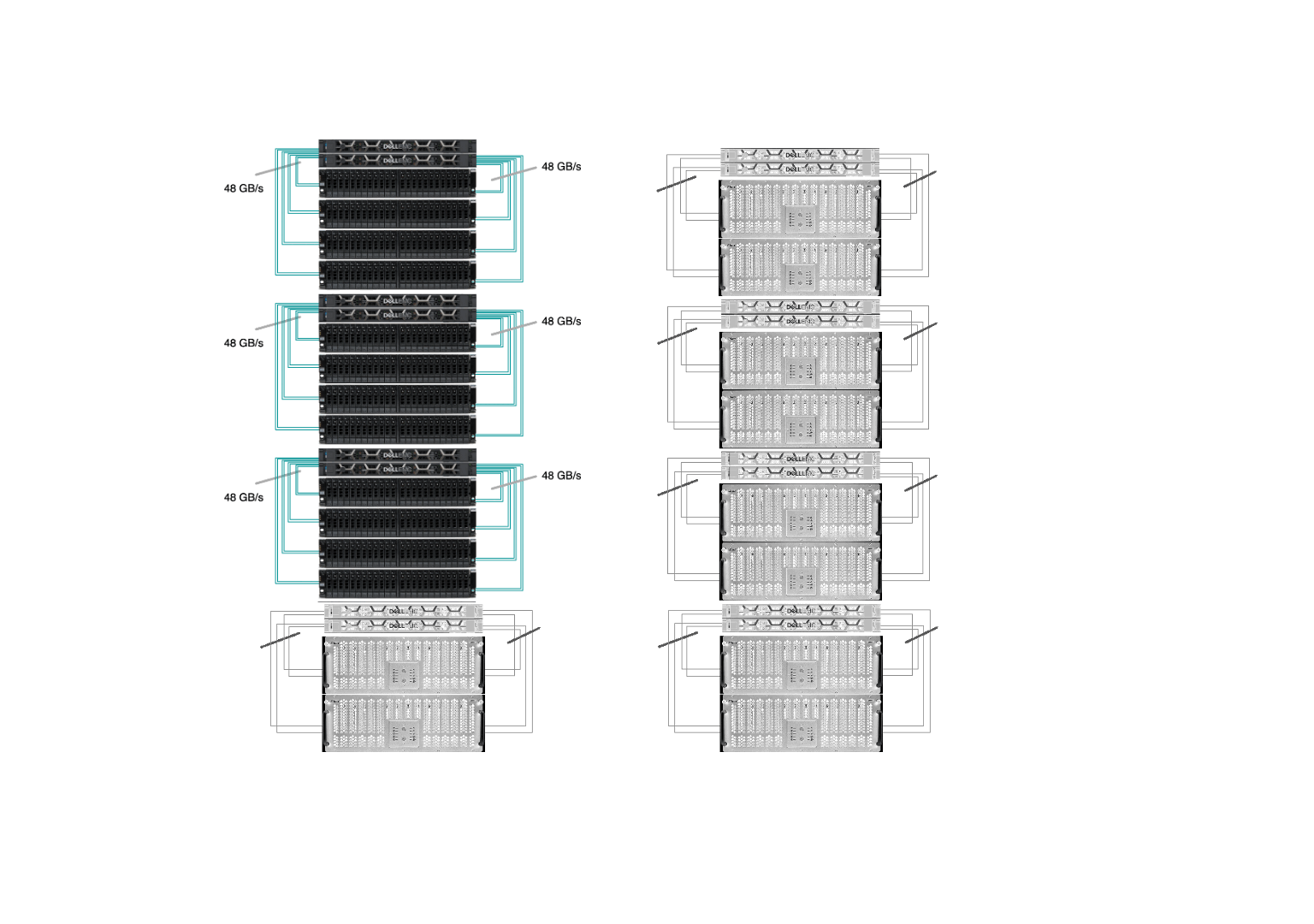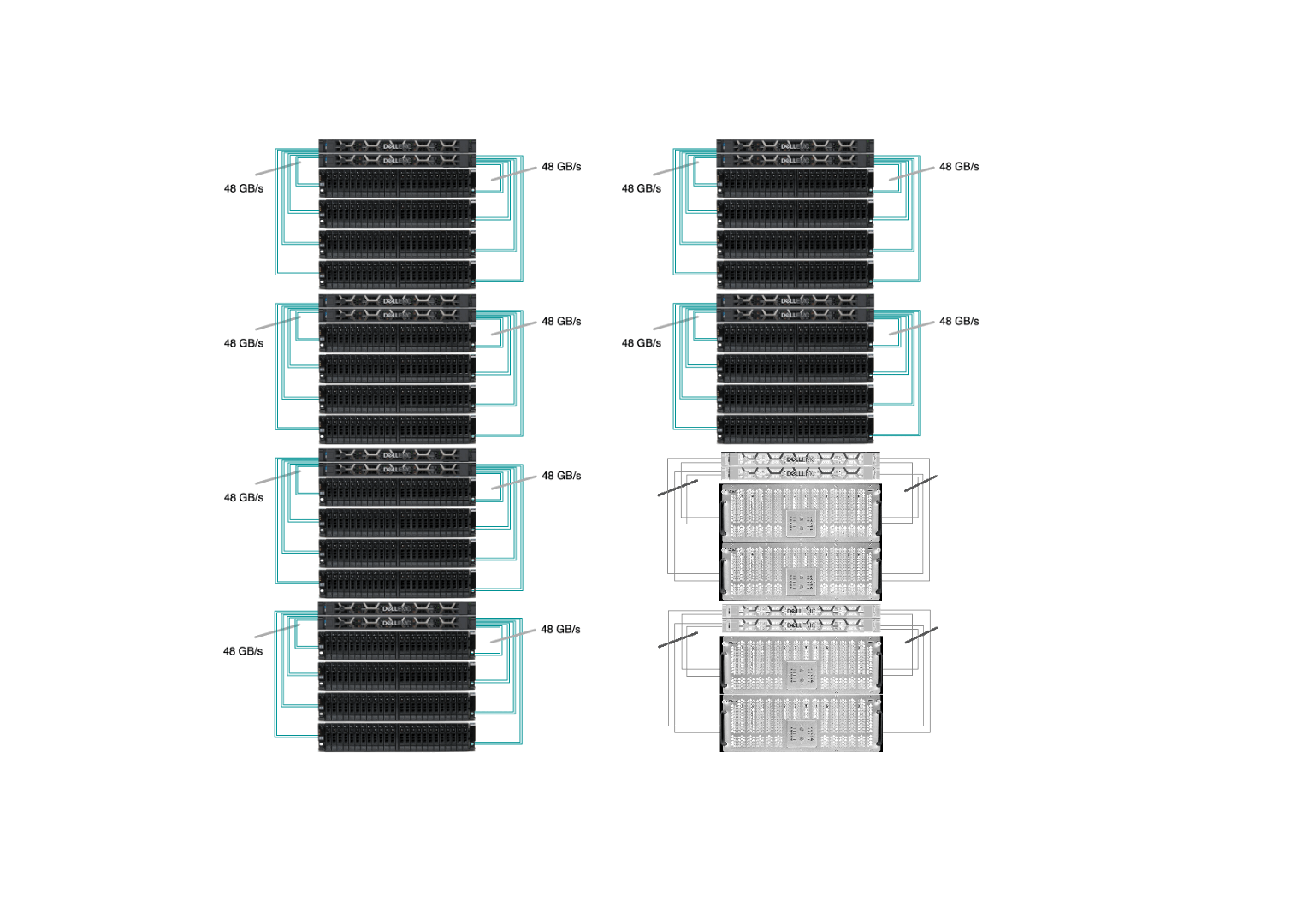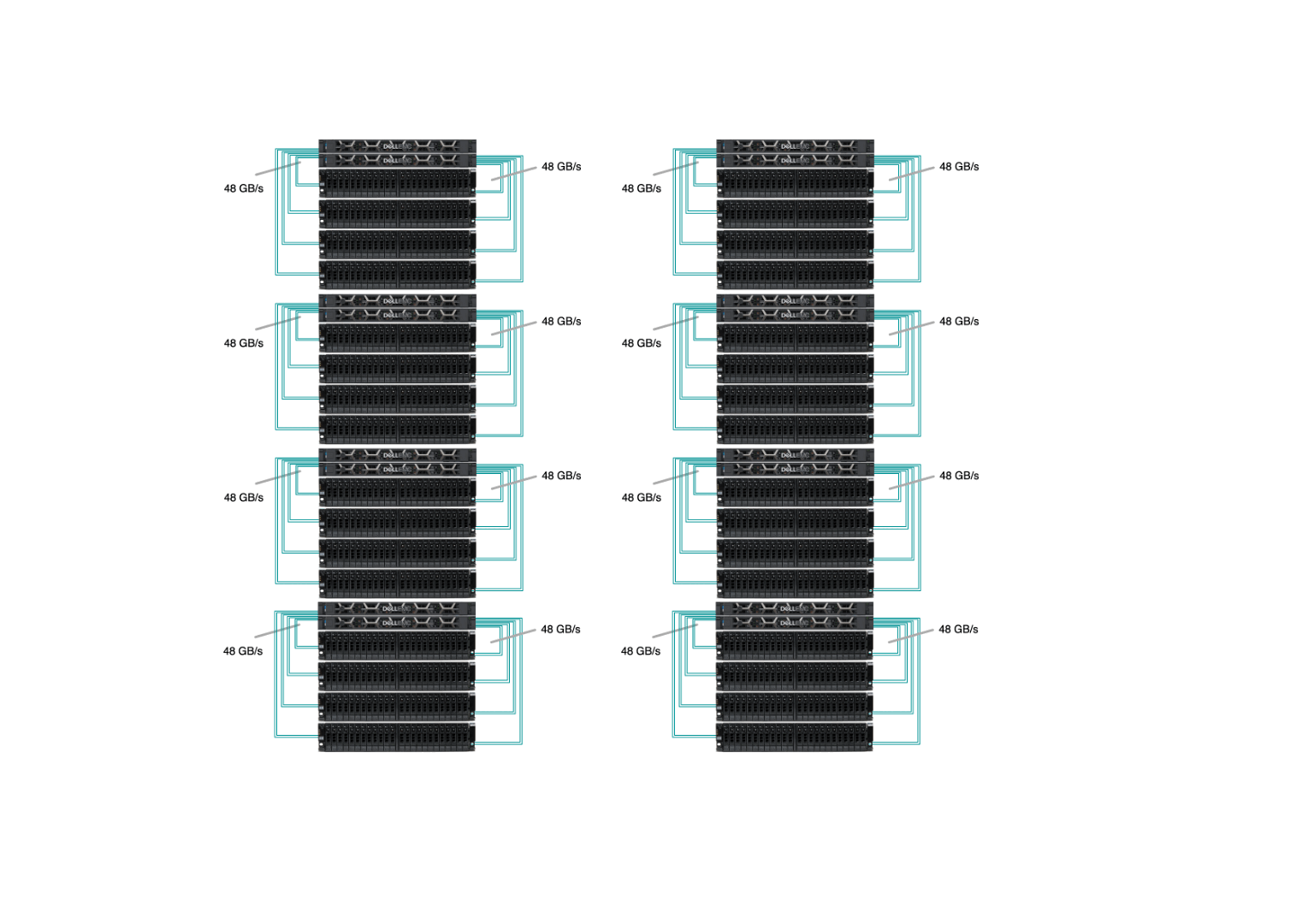
All of those replacements happened while the file system was up and running, serving data to the thousands of computing jobs that run on Sherlock every day. Driven by our commitment to minimize disruptions to users, our top priority was to ensure uninterrupted access to data throughout the upgrade. Data migration is never fun, and we wanted to avoid having to ask users to manually transfer their files to a new, separate storage system. This is why we developed and contributed a new feature in Lustre, which allowed us to seamlessly remove existing storage devices from the file system, before the new flash drives could be added. More technical details about the upgrade have been presented during the LAD’22 conference.
Today, we are happy to announce that the upgrade is officially complete, and Sherlock stands proud with a whopping 9,824 TB of solid-state storage in production. No more spinning disks in sight!
Key benefits
For users, the immediately visible benefits are quicker access to their files, faster data transfers, shorter job execution times for I/O intensive applications. More specifically, every key metric has been improved:
IOPS: over 100x (results may vary, see below)
Backend bandwidth: 6x (128 GB/s to 768 GB/s)
Frontend bandwidth: 2x (200 GB/s to 400 GB/s)
Usable volume: 1.6x (6.1 PB to 9.8 PB)
In terms of measured improvement, the graph below shows the impact of moving to full-flash storage for reading data from 1, 8 and 16 compute nodes, compared to the previous /scratch file system:
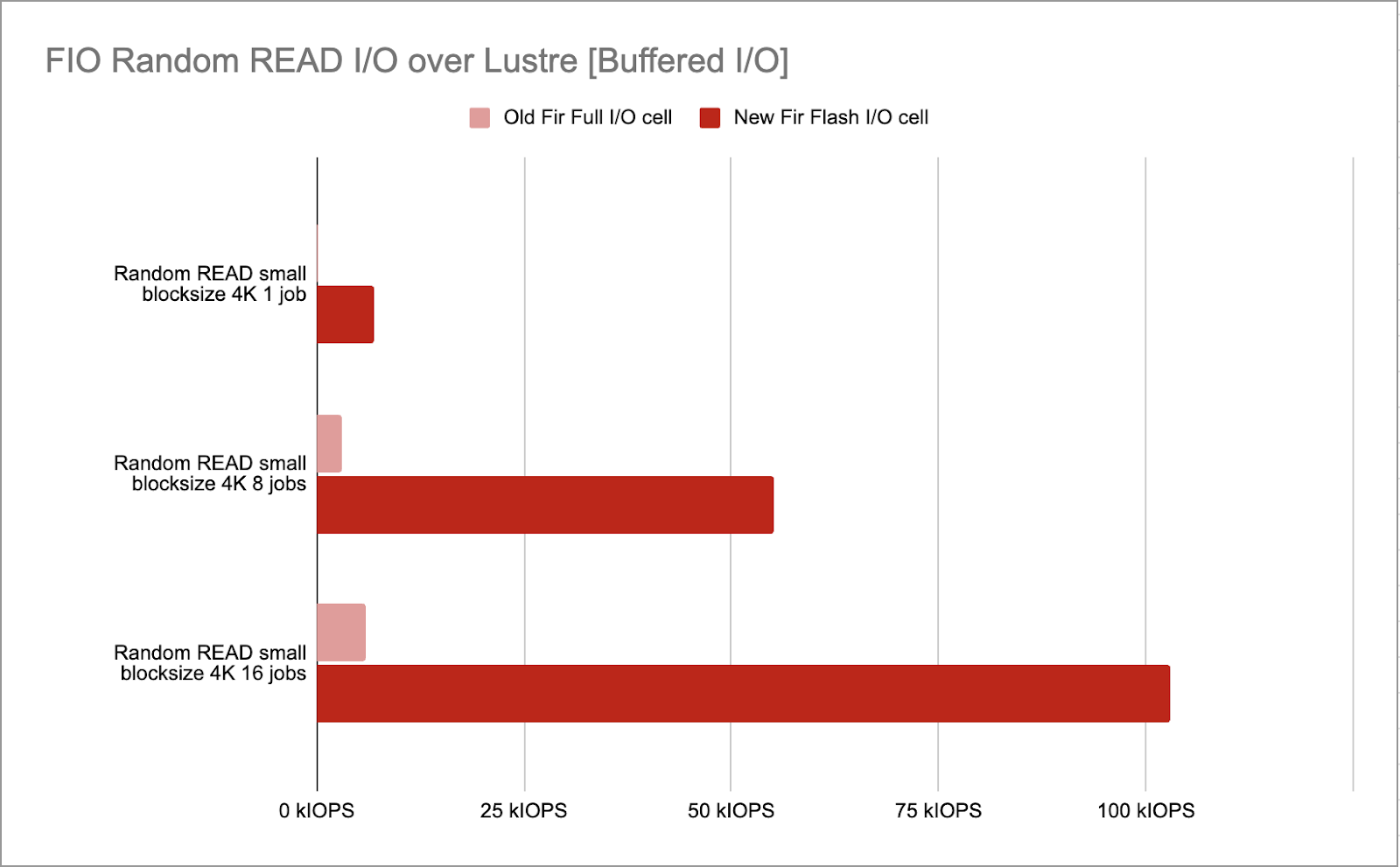
And we even tried to replicate the I/O patterns of AlphaFold, a well-known AI model to predict protein structure, and the benefits are quite significant, with up to 125x speedups in some cases:
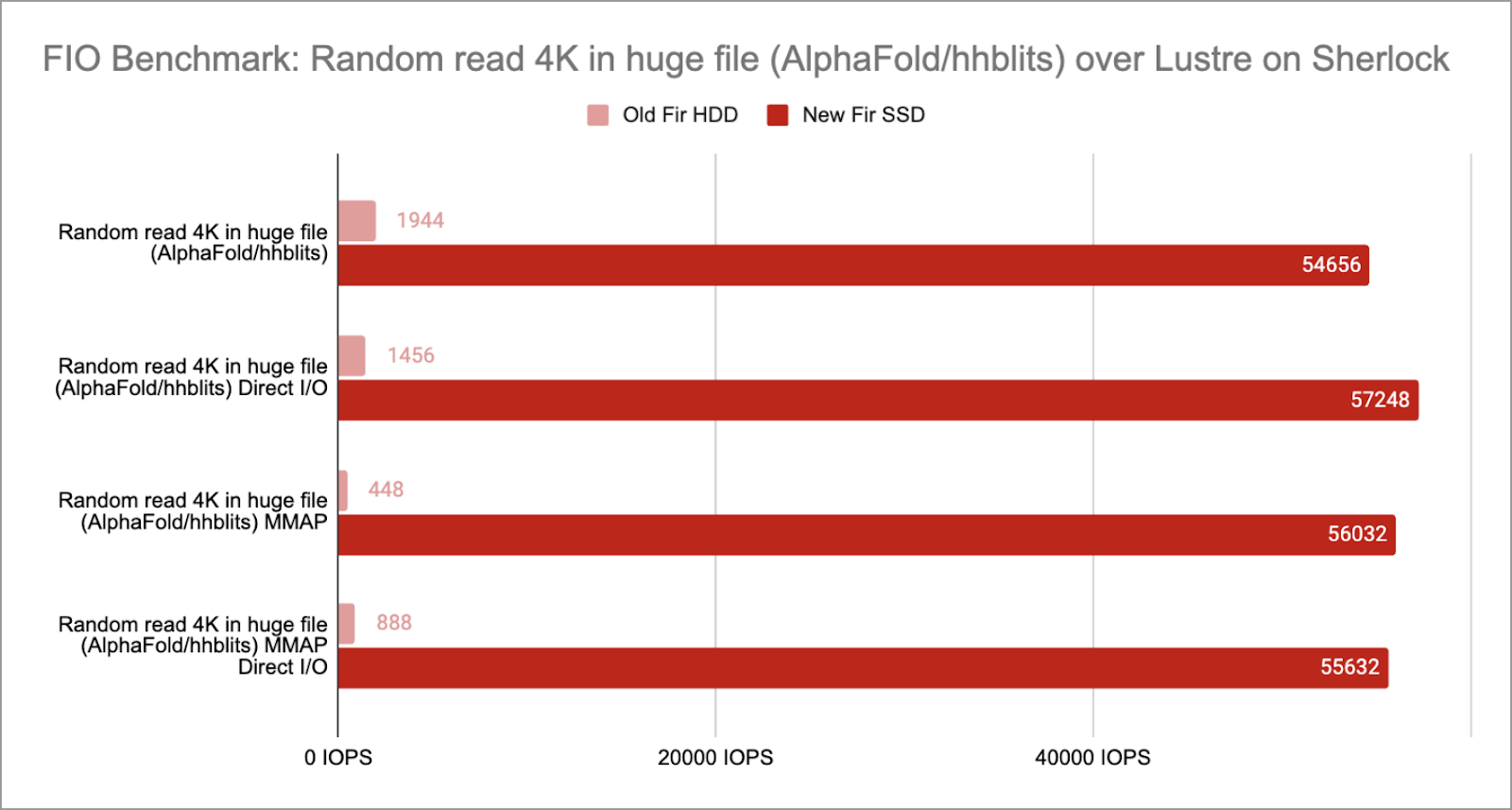
This upgrade is a major improvement that will benefit all Sherlock users, and Sherlock’s enhanced I/O capabilities will allow them to approach data-intensive tasks with unprecedented efficiency. We hope it will help support the ever-increasing computing needs of the Stanford research community, and enable even more breakthroughs and discoveries.
As usual, if you have any question or comment, please don’t hesitate to reach out to Research Computing at [email protected]. 🚀🔧
But first, a little bit of context
Traditionally, High-Performance Computing clusters face a challenge when dealing with modern, data-intensive applications. Existing HPC storage systems, long designed with spinning disks to provide efficient and parallel sequential read/write operations, often become bottlenecks for modern workloads generated by AI/ML or CryoEM applications. Those demand substantial data storage and processing capabilities, putting a strain on traditional systems.
So to accommodate those new needs and future evolution of the HPC I/O landscape, we at Stanford Research Computing, with the generous support of the Vice Provost and Dean of Research, have been hard at work for over two years, revamping Sherlock's scratch with an all-flash system.
And it was not just a matter of taking delivery of a new turn-key system. As most things we do, it was done entirely in-house: from the original vendor-agnostic design, upgrade plan, budget requests, procurement, gradual in-place hardware replacement at the Stanford Research Computing Facility (SRCF), deployment and validation, performance benchmarks, to the final production stages, all of those steps were performed with minimum disruption for all Sherlock users.
The technical details
The /scratch file system on Sherlock is using Lustre, an open-source, parallel file system that supports many requirements of leadership class HPC environments. And as you probably know by now, Stanford Research Computing loves open source! We actively contribute to the Lustre community and are a proud member of OpenSFS, a non-profit industry organization that supports vendor-neutral development and promotion of Lustre.
In Lustre, file metadata and data are stored separately, with Object Storage Servers (OSS) serving file data on the network. Each OSS pair and associated storage devices forms an I/O cell, and Sherlock's scratch has just bid farewell to its old HDD-based I/O cells. In their place, new flash-based I/O cells have taken the stage, each equipped with 96 x 15.35TB SSDs, delivering mind-blowing performance.
Sherlock’s /scratch has 8 I/O cells and the goal was to replace every one of them. Our new I/O cell has 2 OSS with Infiniband HDR at 200Gb/s (or 25GB/s) connected to 4 storage chassis, each with 24 x 15.35TB SSD (dual-attached 12Gb/s SAS), as pictured below:
Of course, you can’t just replace each individual rotating hard-drive with a SSD, there are some infrastructure changes required, and some reconfiguration needed. The upgrade, executed between January 2023 and January 2024, was a seamless transition. Old HDD-based I/O cells were gracefully retired, one by one, while flash-based ones progressively replaced them, gradually boosting performance for all Sherlock users throughout the year.
All of those replacements happened while the file system was up and running, serving data to the thousands of computing jobs that run on Sherlock every day. Driven by our commitment to minimize disruptions to users, our top priority was to ensure uninterrupted access to data throughout the upgrade. Data migration is never fun, and we wanted to avoid having to ask users to manually transfer their files to a new, separate storage system. This is why we developed and contributed a new feature in Lustre, which allowed us to seamlessly remove existing storage devices from the file system, before the new flash drives could be added. More technical details about the upgrade have been presented during the LAD’22 conference.
Today, we are happy to announce that the upgrade is officially complete, and Sherlock stands proud with a whopping 9,824 TB of solid-state storage in production. No more spinning disks in sight!
Key benefits
For users, the immediately visible benefits are quicker access to their files, faster data transfers, shorter job execution times for I/O intensive applications. More specifically, every key metric has been improved:
IOPS: over 100x (results may vary, see below)
Backend bandwidth: 6x (128 GB/s to 768 GB/s)
Frontend bandwidth: 2x (200 GB/s to 400 GB/s)
Usable volume: 1.6x (6.1 PB to 9.8 PB)
In terms of measured improvement, the graph below shows the impact of moving to full-flash storage for reading data from 1, 8 and 16 compute nodes, compared to the previous /scratch file system:
And we even tried to replicate the I/O patterns of AlphaFold, a well-known AI model to predict protein structure, and the benefits are quite significant, with up to 125x speedups in some cases:
This upgrade is a major improvement that will benefit all Sherlock users, and Sherlock’s enhanced I/O capabilities will allow them to approach data-intensive tasks with unprecedented efficiency. We hope it will help support the ever-increasing computing needs of the Stanford research community, and enable even more breakthroughs and discoveries.
As usual, if you have any question or comment, please don’t hesitate to reach out to Research Computing at [email protected]. 🚀🔧